

Tässä blogisarjassa käydään läpi, miten Googlen tarjoamia palveluita voidaan yhdistää jalostamaan ja rikastamaan Google Analytics dataa. Edellisessä blogissa tutustuttiin BigQueryn SQL-syntaksiin, ja luotiin Google Analytics-dataan uusi sessiotunniste, jota hyödynnettiin laskemaan sessiokohtaisia avainlukuja.
Tässä blogissa tutustutaan BigQueryn natiiveihin mallintamistyökaluihin, ja hyödynnetään edellisessä blogissa luodut tiedot segmentoimaan verkkosivujen käyttäjät erilaisiin kategorioihin.
BQML
Vielä kymmenisen vuotta sitten koneoppivien mallien rakentaminen oli asiantuntijoiden erikoisaluetta. Tänä päivänä löytyy useita helppokäyttöisiä vaihtoehtoja, joilla pystytään rakentamaan kompleksisia malleja jopa ilman minkäänlaista koodaustaitoa. Tämä ei tietysti tarkoita sitä, etteikö mallintamiseen enää tarvittaisi asiantuntijoita, mutta kevyen käyttöönoton kynnys on madaltunut huomattavasti, joka on mahdollistanut jopa kasuaaleimmille käyttäjille ennustavaan analytiikkaan siirtymisen.
BigQuery:ssä näitä malleja on tukku, ja usealle löytyy kattavia tutoriaaleja. Malleja pystytään luomaan natiivisti BigQuery:ssä, mutta niitä voidaan myös tuoda muista järjestelmistä. BigQuery:ssä luotuja malleja voidaan myös exportata, ja hyödyntää muualla. Esimerkkejä BigQuery:ssä luotavista malleista ovat regressiomallit, puumallit, klusterointimallit sekä aikasarjamallit. Näiden työkalujen avulla pystyy monipuolisesti rikastamaan dataa konkreettisella tavalla, esimerkiksi luomalla myyntiennusteita, konversio-odotusarvoja tai käyttäjäklusterointeja.
Käyttäjäsegmentointi
Viime blogissa laskettiin valmiiksi sessiokohtaisia avainlukuja, joten nyt on valmiina klusterointiin soveltuva datakokonaisuus. Yksi suosituimmista klusterointimalleista on nimeltään K-means. Käytännössä se toimii niin, että käyttäjä syöttää malliin numeerista dataa, ja klustereiden määrä (k), ja algoritmi luo datasta k-määrän mahdollisimman erilaisia klustereita, ja klassifioi jokaisen rivin yhteen näistä klustereista. Kun malli on luotu, voidaan klustereiden määritelmät hyödyntää jatkuvasti uusien rivien klassifiointiin.
Viime kerralla luotiin myös näkymän nimeltä events_with_session2022, joka sisälsi tämän vuoden eventtidatan, jalostettuna omalla sessiotunnisteella, jonka nimesimme session_id:ksi. Tätä sitten kyseltiin niin, että saatiin sessiokohtaisesti laskettua seuraavat avainluvut: klikkien määrä, eventtien määrä, sivustolla vietetty aika minuuteissa. Tässä voisi yhtä hyvin käyttää jotain muita avainlukuja, jotka kuvaavat paremmin tiettyjen asiakassegmenttien käyttäytymistä, mutta nämä valittiin lähinnä sen takia että ne olivat helposti laskettavissa. Optimaalisesti tässä välissä mietittäisiin tarkemmin mahdollisia käyttäjäsegmenttejä, ja miten niitä pystyttäisiin datalla selittämään, jatkojalostettaisiin mahdollisesti dataa, jotta saataisiin mahdollisimman kuvaavat mittarit käyttöön. Tällä tavalla pystyisi myös valistetusti päättämään klustereiden määrä.
Mutta koska elämme reaalimaailmassa, näitä helposti laskettavissa olevia mittareita hyödynnetään, ja päätetään että ryhmitellään verkkosivuston käyttäjät neljään eri kategoriaan.
BigQueryn mallintamissyntaksiin kuuluu kaksi elementtiä. Ensiksi syötetään mallin tiedot, sitten kysellään malliin syötettävä data.
CREATE OR REPLACE MODEL
`[project_id.dataset.id].session_clustering_model` OPTIONS(model_type='kmeans',num_clusters=4) AS
Yllä olevassa koodipätkässä siis nimetään ensin malli, ja sen jälkeen syötetään siihen tiedot: haluamme luoda K-means mallin neljälle klusterillä. Sitten tuon perään syötetään data-kysely:
SELECT * EXCEPT(session_id) FROM (
SELECT
session_id,
SUM(CASE WHEN event_name = 'click' THEN 1 ELSE 0 END) AS clicks,
(MAX(event_timestamp) - MIN(event_timestamp))/1000000/60 AS minutes_on_site,
COUNT(1) AS events
FROM `[project_id.dataset.id].events_with_session2022`
GROUP BY session_id)
Tässä kyselyssä lasketaan ensiksi sessiokohtaiset luvut, ja sen jälkeen valitaan kaikki muut kentät paitsi sessiotunnisteen. Kun nämä kaksi kyselyä yhdistetään, saadaan kokonainen mallintamiskysely.
CREATE OR REPLACE MODEL
`[project_id.dataset.id].session_clustering_model` OPTIONS(model_type='kmeans',num_clusters=4) AS
SELECT * EXCEPT(session_id) FROM (
SELECT
session_id,
SUM(CASE WHEN event_name = 'click' THEN 1 ELSE 0 END) AS clicks,
(MAX(event_timestamp) - MIN(event_timestamp))/1000000/60 AS minutes_on_site,
COUNT(1) AS events
FROM `[project_id.dataset.id].events_with_session2022`
GROUP BY session_id)
Tätä kyselyä ajettaessa saadaan hetkessä käyttöön mallin, joka hyödyntää sitä dataa, jota siihen on syötetty. Kun malli on valmis, sitä voi jatkuvasti hyödyntää evalvoimaan uutta dataa ja uusia sessioita. Tämä malli löytyy projektivalikon Models kohdasta, ja jos luodun mallin avaa siitä ja navigoi Evaluation-välilehteen, niin pääsee tarkastamaan klustereiden tietoja.
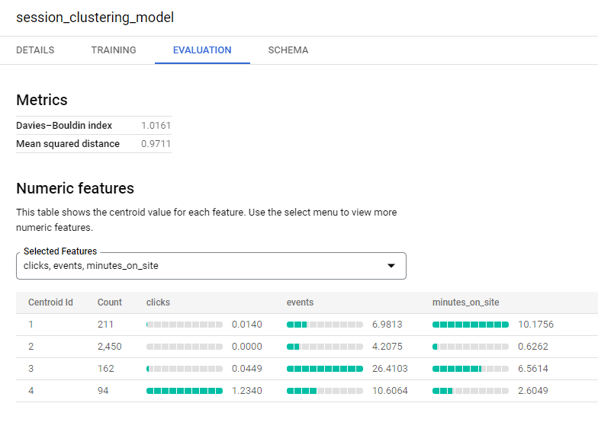
Käyttäjäsegmentit
Tästä voidaan nähdä neljän klusterin keskiarvot jokaiselle mittarille, jotka siihen on syötetty. Näiden arvojen perusteella voidaan keksiä klustereille sopivia selitteitä, esimerkiksi ensimmäinen klusteri koostuu käyttäjistä, jotka klikkaavat vähän ja keräävät jonkun verran eventtejä, mutta viettävät paljon aikaa sivustolla – ehkä nämä ovat blogien lukijoita? Neljäs klusteri taas koostuu melkein kaikista edes kerran klikanneista käyttäjistä. Nämä käyttäjät näyttäisivät navigoivan sivustoa aktiivisemmin, ehkä voisimme olettaa heidän etsivän jotain tiettyä sivustoltamme. Toinen klusteri taas koostuu käyttäjistä, jotka tulevat sivustolle, ja häipyvät melkein samantien. Ne voisivat olla käyttäjiä, jotka etsivät jotain tiettyä, ja löytävät sen samantien. Jos prosessin alussa olisi ollut selkeä kuva niistä käyttäjäsegmenteistä, joita oltaisi lähdetty rakentamaan, niin tässä vaiheessa ne voitaisiin yhdistää mallin tuloksiin.
Valmista mallia voidaan jatkossa käyttää myös uuteen dataan. Eli syöttämällä uutta samanmuotoista tietoa, voidaan sessiokohtaisesti saada kiinni mihin neljästä klusterista mikäkin sessio kuuluu. Tällöin luomme uuden näkymän, johon tulee sessiokohtaisesti yllämääritetyt tiedot, sekä mallin evaluoima tuotos.
CREATE OR REPLACE VIEW `[project_id.dataset.id].session_with_clusters` AS
WITH sessions AS (SELECT
session_id,
sum(CASE WHEN event_name = 'click' THEN 1 ELSE 0 END) AS clicks,
(MAX(event_timestamp) – MIN(event_timestamp))/1000000/60 AS minutes_on_site,
COUNT(1) AS events
FROM `[project_id.dataset.id].events_with_session2022`
GROUP BY session_id)
SELECT * EXCEPT(nearest_centroids_distance) FROM ML.PREDICT(MODEL `[project_id.dataset.id].session_clustering_model`, (SELECT * FROM sessions ))
Näkymää voidaan yhdistää sessiotunnisteella eventtitauluun, jolloin pystytään tekemään syvempää analyysiä eri klustereiden käyttäytymisestä. Jos tässä oltaisiin käytetty Googlen omaa valmista sessiotunnistetta, tai tehty tämän harjoitus käyttäjätasoisesti, klusteritiedot voitaisiin viedä takaisin Google Analytics:iin, tai Google Ads:iin, ja rakentaa mainontakampanjointia sen mukaan, miten käyttäjät ovat käyttäytyneet sivustolla.
Tässä blogissa hyödynnettiin edellisessä blogissa rakennetut datasetit mallintamiseen. On rakentannettu K-means klusterointimalli, joka luokittelee jokaista sessiota klusteriin sen mukaan miten session sisällä käyttäjä käyttäytyy sivustolla. Sen jälkeen on käytetty tätä mallia rakentamaan näkymä, jonka kautta pystytään yhdistämään nämä klusterit eventtitauluun syvempää analyysiä varten.
Jos sinua kiinnostaa ennustavan analytiikan hyödyntäminen organisaatiossasi, ota yhteyttä!

Lue myös blogisarjan ensimmäinen osa!

